The Test Automation Reference Model
There is no shortage of test automation tools. The independent software testing company Cigniti maintains a list of 100 commercial and open source tools [1]. The web site Opensourcetesting.org features over 360 open source tools in 20 categories [2]. Add to this the vast array of tools that are developed in-house and organisations are truly spoilt for choice when it comes to test automation.
Faced with so many options, it is not surprising that organisations find it difficult to choose test automation tools. A lack of clear requirements for the tool, overlapping features and inconsistent terminology all contribute to the problem.
Organisations often fail to identify a clear set of requirements for test automation tools. One of many myths surrounding test automation is that automation is driven by products. Commercial tool vendors like to promote the idea that a single “best of breed” tool can meet all of an organisation’s requirements. For open source tools, “reputation” and “word of mouth” often drive tool selection rather than a clear set of requirements.
Tools implement different and sometimes overlapping sets of features and are sometimes based on a conceptual view of testing that may not be aligned with an organisation’s approach. There are tools that incorporate whole testing “ideologies” based on very specific approaches to the software development life cycle such as Test or Behaviour Driven Development (TDD and BDD).
While such diversity creates a very rich marketplace for automation tools, sometimes the inconsistent terminology that results can make it difficult to compare the features of different tools and communicate their differences.
The Test Automation Reference Model (TARM) is a conceptual framework for understanding, comparing and selecting test automation tools. It identifies the common features and components of a test automation framework and can also be used as a reference architecture for developing in-house frameworks.
I am going to start the guided tour of the TARM with a brief discussion of the two universal test automation components - drivers and stubs.
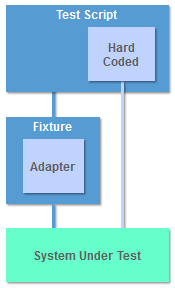
Drivers and Stubs I imagine that most software developers have written drivers and stubs at some point in their career. Drivers automate the steps of a test procedure and interact with the system under test (SUT) by passing it test data. Drivers are also responsible for checking that the actual results returned by the SUT are the same as the expected outcome of the test. Normally test data is hard coded in the driver which means a separate driver (and often a separate stub) is required for each test. Hard coding the test data also means that the script needs to be changed if the SUT changes, when new test cases are required or if the test data changes.
Stubs simulate missing SUT components, standing in for components that may not have been coded yet, components that have bugs, and components that are impractical to include in a test (such as a live interface to a banking system). Stubs can also be useful for forcing exceptions that would not be encountered in normal operation.

Drivers and stubs don’t scale well. Coding a large number of stand alone drivers and stubs is time consuming and offers little opportunity for reuse. If a suite of related tests are implemented with drivers and stubs, a control script is required to launch the drivers in the correct sequence and take into account any dependencies between test cases.

Many of these problems can be resolved by basing the drivers and stubs on a sound architectural design which is precisely what the TARM provides.
Capture-Replay Tools One approach that attempts to overcomes some of the problems associated with drivers and stubs, is to record the steps of a test procedure using a capture-replay tool. These tools can be used to create drivers but hard coded stubs will still be required to simulate missing SUT components.
Capture tools work by inserting themselves between a human tester and the SUT. The tester then follows the steps in a test procedure while the capture tool records the tester’s actions in a form that can be later re-played by the replay tool.
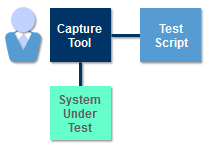
Capture-replay solves the problem of repetitive coding and can create the illusion of improved productivity as long as there are no changes to the SUT that trigger the need to re-capture the test. The improved productivity offered by capture-replay tools is reduced each time a test needs to be re-captured, making capture-replay less suitable for testing a SUT that frequently changes.
Capture-replay doesn’t scale well either. It is not unusual for teams to become overwhelmed by a large number of isolated test scripts. Test data is hard coded in captured test scripts, in the same way as a driver except that it may be encoded in some obscure way that reflects details of the user interface. Execution of test suites will also require a control script to launch the captured scripts in the correct sequence.
Automating Test Procedures So with these problems in mind, we will start our tour of the TARM. In fact, our discussion of drivers and stubs has not been wasted because we are going to start the tour with the Test Script component which is essentially the same as a driver except that it has access to all the services provided by other components in the TARM. 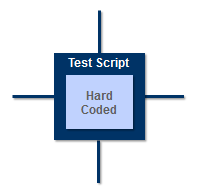
Not all test automation tools implement the full set of TARM components which means that services normally provided by a missing component will need to be hard coded in the test script. In the extreme case, none of the TARM components are present which means that all services normally provided by the missing components will be hard coded. In other words we will need to code traditional drivers!
Interacting With the SUT Test scripts need to interact with the SUT. When the source code of a test script and the SUT are compiled together and share the same address space, the test script interacts with the SUT via function calls that pass test data to the SUT. This is commonly known as white-box testing. The various xUnit [3] frameworks are a good example of white box testing tools.
Black-box testing requires the test script to interact with the SUT via a standard interface or API implemented by the SUT. In some cases this may be a custom test API but more often it is a normal API.
Although testing through an API is often the fastest and preferred approach to interacting with the SUT, there are many times when it becomes necessary to interact via the user interface (UI). Sometimes this is because a suitable API does not exist and at other times it is a result of poor architectural decisions that result in important features embedded in the code that implements the user interface. Interacting through the user interface will require some form of UI Inspector that exposes the details of UI elements so that they can be mapped to a test script.
A Fixture removes the need to include code that interacts with the SUT in every script. Fixtures are written once and then called by the test script each time it needs to interact with the SUT. Fixtures may also be used to provide an abstract view of an API or UI that is more suitable for testing.
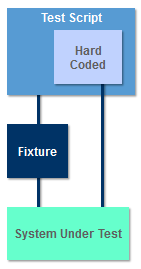
Adapters are a simple type of fixture that provides minimal abstraction. Adapters are useful for a variety of purposes:
- converting test data format to the format expected by the SUT
- converting between APIs (especially offering public access to a normally private API)
- providing API bindings for different programming languages
- defining a standard API for accessing the elements of a UI
A good example of a pure adapter is AutoIT [4]. AutoIT is a scripting tool based on the Basic programming language. The AutoIT language includes statements that interact directly with Windows UIs. Included with AutoIT is an adapter called AutoITX, which provides an API that can be used by other programming languages to interact with a Windows UI.
Selenium Web Driver [5] probably falls somewhere between a fixture and an adapter. While it provides some abstraction for web based user interfaces, its main purpose is to provide a standard API that allowing test scripts to access the private automation APIs of many popular browsers.
Simulating Missing SUT Components As we have discussed, the purpose of a stub is to simulate missing components. Stubs are often coded to simply accept parameters and return specific values when they are called by the SUT. In some cases, stubs are coded to provide a more realistic simulation that might include the decisions and calculations normally performed by the missing component.
Stubs are required for each component that is missing and in some cases for each test that is performed. This quickly leads to a large number of hard coded stubs with limited opportunity for reuse. Mock objects are based on reusable framework such as JMock [6], that reduces the amount of hard coding required. Rather than program code, a declarative approach is used to define the behaviour of “mock objects”.
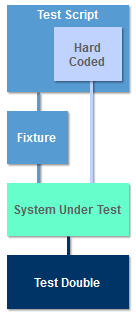
To avoid confusion between stubs and mocks, we shall refer to any TARM component designed to simulate the behaviour of missing SUT components as a Test Double. See Martin Fowler’s classic article Mocks Aren’t Stubs for more detail on test doubles [7].
Storing Test Data As we have seen, hard coding test data in a test script lacks flexibility. Test scripts are more flexible when test data is stored and managed external to the test script.
Storing test data in simple text files is one approach that allows the test data to be managed outside the test script. When test cases are straightforward, text files can be quite effective but for more complex test cases, test scripts often become more complicated than necessary.
A better approach is to the store test data in a format that reflects the underlying structure of the test case. This approach also allows test cases to be designed and reviewed early in a project with the actual values of the test data added later before testing commences.

Test cases are designed to achieve an objective such as checking that the software is fit for its intended purpose, checking that it conforms to its requirements or identifying failures in the software.
Examples of tools that provide separate Test Case Management and Test Data Management components, include Fitness [8] and Testlink [9]. Some tools such as Graph Walker [10] and Acts [11] go beyond simply managing test cases and provide the ability to generate test cases using techniques such as model based testing and all-pairs testing.
Executing a Suite of Test Cases A test suite is a collection of test cases that are executed together. Often there are dependencies between the individual tests in a suite. A common dependency is for the post-conditions of one test case to become the pre-conditions for the following test. One way of ensuring that test cases are executed in the correct sequence is to store test data in the rows of a Table. The order of the rows in the table will then determine the order in which the test cases are executed.
When this approach is used, a parser is required to extract the test data from the rows and columns of the table. The parser could be be hard coded in each of the test scripts, but a better approach is to implement a reusable Parser component.
Because each row of a table has identical columns, tables can only store data in a single format. When the tests in a test suite need different data formats, several tables will be needed, one for each data format required.
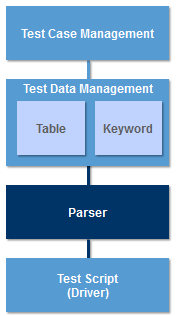
Normally the steps of a test procedure and its interaction with the SUT are hard coded in a test script. Keyword testing uses a predefined set of keywords to describe the steps of a test procedure instead. This approach means that test procedures can be stored and managed external to the test script in the same way as test data. Keyword testing also removes the need for multiple tables to accommodate different data formats.
The set of predefined keywords is often described in a Domain Specific Language (DSL) that includes keywords to:
- launch the SUT
- set up pre-conditions
- interact with the SUT
- check internal states of the SUT
- compare the actual and expected results of a test
- ensure that post-conditions have been satisfied.
Most DSLs also define a set of parameters for each of the keywords. Keywords that interact with the SUT will require fixtures to map their parameters to an API or user interface. Keyword fixtures may also provide abstract ways of interacting with a SUT that hide complex technical details.
Some keyword tools are based on a predefined DSL. For example, the Cuke language used by Cucumber [12]. Other tools such as Robot [13] allow the definition of customised DSLs. To simplify parsing, many keyword tools store their DSLs in tables. This can cause confusion with some tools using tables to store test data and others using tables to store keywords and their parameters. Fitnesse [8] is an example of a tool that supports both table and keyword testing.
Keyword testing is sometimes known as “script less” testing. Once the keyword fixtures and a suitable parser have been developed, there is no further code to write. New test cases can be created using the existing keywords defined in the DSL. Changes to the SUT, such as adding a new UI element, will of course require additional fixtures to be developed.
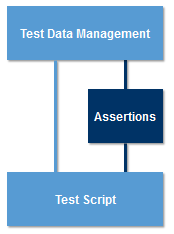
Deciding If the Test Passed or Failed When the expected outcome of a test case and the actual result obtained from the SUT are the same, the test passes. When they are different, the test fails. When the expected outcome and actual result are both simple values, they can be compared using a straightforward test for equality. Comparing more complex values may involve operations such as casting string values into floating point numbers, testing two objects for equality or checking the internal state of the SUT.
Hard coding the operations to determine if a test has passed once again leads to code redundancy and a lack of reuse. For this reason, many test tools implement an Assertion component to compare the expected outcomes and actual results. A test script simply needs to “assert” that the actual result should be the same as the expected outcome and the assertion component will automatically handle any operations necessary to perform the comparison.
The person designing a test case usually determines the expected outcomes of the test. But in some situations, it is not easy to determine what the expected outcome should be. When this is the case, a test oracle is required. A Test Oracle is a component that determines what the expected outcome of a test should be.
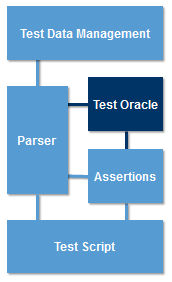
To reduce the possibility of human error, a test oracle can be used to design test cases (static oracle). For example, a spreadsheet might be used to calculate the expected outcomes based on some complex formula.
A dynamic test oracle calculates the expected result as a test case is executed. A popular choice for a dynamic test oracle is a previous version of the SUT which is trusted to give the correct results. This approach is often known as A-B testing because two versions of the SUT (version A and B) are required for the test (not to be confused with A-B testing used to compare the popularity of two different versions of a web page).
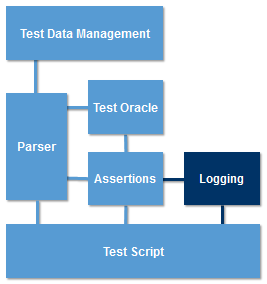
Executing a Suite of Test Cases Even when a test fails, the execution of a suite of tests must proceed without human intervention. The Logging component logs test results (pass or fail) so they can be reviewed later. The logging component is usually linked to the assertions component so that when an assertion fails it is automatically logged and the test proceeds to the next test case. Many Logging components also provide the ability to log other things such as the overall progress of the test.
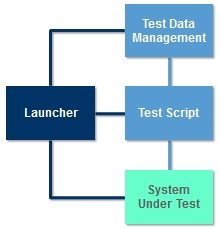
When there are dependencies between the test cases in a test suite, a Launcher component is required to execute the test cases in the correct sequence. The launcher is also responsible for:
- launching the correct test script
- launching the SUT
- establishing any system wide pre-conditions such as establishing network or database connections
- selecting the correct test data for the test
- establishing the mechanism that the test script uses to interact with the SUT
Capture-Replay Tools and the TARM We have almost completed our tour of the TARM components. Before we step back and view the entire model, we are going to briefly return to capture-replay tools. Capture-replay tools that are integrated into the TARM can overcome some of the problems associated with stand alone capture replay tools that we discussed earlier. Integrated capture-replay tools are able to use the services provided by other TARM components. This increases the reuse of code and provides an improved ability to scale.
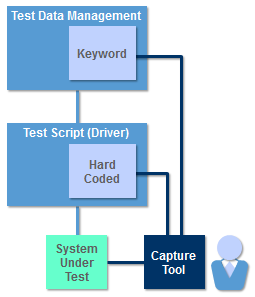
Integrated capture-replay tools fall into two categories, depending on the approach they used for capturing steps of a test procedure:
- tools such as AutoIt’s [4] Macro Generator capture steps as program code; and
- tools such as Selenium IDE [14] capture steps as keywords
Test procedures captured as program code are replayed by executing the captured test script. The script will invoke the services of other TARM components when they are required.
Test procedures captured as keywords require a parser to parse the keywords. Many tools such as Selenium ID [14] also provide the ability to export captured tests as program code.
Both approaches still suffer from sensitivity to change and will require a control script to launch tests a suite of tests in the correct sequence.
The Full Test Automation Reference Model We have now completed our tour of the TARM and present the full model below.
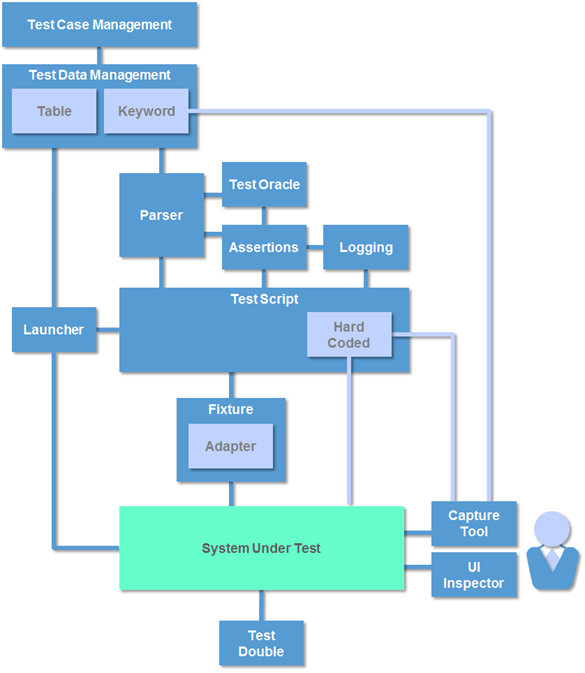
 The Test Automation Reference Model
The Test Automation Reference Model